I spent a lot of last year, getting excited about data science and machine learning.
This year’s new year resolution is to complete

I’ve also got

On the way, but Amazon needs 11 days to deliver it, so it’s not on the shelf ready yet.
I spent a lot of last year, getting excited about data science and machine learning.
This year’s new year resolution is to complete
I’ve also got
On the way, but Amazon needs 11 days to deliver it, so it’s not on the shelf ready yet.
I will be giving a talk entitled ‘Machine Learning with Clojure’ on 6th November. The talk will focus on what aspects of machine learning clojure is good for and discuss some of the pitfalls.
Sign up for the talk at skillsmatter.
I recently attended the Strata Conference in London. This is the latest incarnation of O’Reilly’s Data conferences. There was a palpable sense of excitement in the air. Obviously most of the attendees were already ‘data’ aficionados, but it’s clear that ‘data’ in various forms is on the radar for governments, large corporations and the developer communities.
If you asked anyone when ‘big data’ started to become important most people would say they started to hear about it, maybe 5 years ago. George Dyson blew that idea away in his keynote talk which talked about various data projects as far back as the 1950’s. He told us a great, easy to remember stat - In 1953, the total amount of RAM in existence worldwide was just 53kb.
Having said that it’s still early days for most companies looking to leverage their data. A few of the speakers mentioned that some companies are saying We’ve got all this data, what can we do with it? The consensus was that this isn’t the right approach, rather find a problem that you need to solve, then look at the data .
It’s also true that a lot of really interesting, important and relevant questions can be answered with datasets that fit on a laptop. It’s not always about tackling problems at Google scale, we should be focusing on the important data instead. All sorts of changes in society are coming when we start measuring and analysing more and better than we do today.
Some of those changes are going to be difficult from a morality and privacy point of view, but I’m confident that by using data well we’ll have opportunity to improve many areas.
Exciting times.
In my previous post, Clojure STM - What? Why? How? I gave a high level run through of Software Transactional Memory in clojure via Multiversion concurrency control. The first example demonstrated how a transfer between two bank accounts could be achieved transactionally. A second example talked about a report over all the bank accounts in the system, whilst transactions like those in the first example were proceeding.
This second example prompted some discussion on reddit.com. The main question was ‘are the values of the refs in all the accounts consistent’
This post is an investigation of the points raised
Lets look again at the code of that example…
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
The key point to notice here that the current value of each account is
retrieved via the deref in the call (map deref accounts). This makes
the current value of the ref the in-transaction value for the
remainder of the transaction. Since there is a call to deref for
each account and traversing the list takes finite time
(especially since map returns a lazy sequence) is there a
potential for a change to a value in the accounts collection while
we’re traversing the list?
All reads of Refs will see a consistent snapshot of the ‘Ref world’ as
of the starting point of the transaction (its ‘read point’). The
transaction will see any changes it has made. This is called the
in-transaction-value.
How can we validate that this is the case? Here are two functions
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
UPDATED: Code above updated at 10:17GMT 03 Jul 2014 following comments in #clojure by hiredman
Given these two methods we can engineer a situation where we
(deref ref2) in one transaction, update ref1 a few times in other
transactions, then (deref ref1) in the first transaction. If the
assertion about a consistent snapshot is correct then the updates to
ref1 shouldn’t be visible in our first transaction.
So what happens when we run this?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
The r1=3 result is not what we’re expecting. If the read of
ref2 creates a ‘read point’ that all other refs are aligned with,
the updates to ref1 should not be visible here. Also we see that
the READ transaction is unexpectedly re-starting.
Remember that the ‘READ’ transaction here is read-only.
It seems that clojure has something of an inconsistency here. When the ‘READ’ transaction is complete, the runtime looks for an entry in the history of all the refs from before the transaction started. If it finds an entry then the transaction completes, otherwise the transaction is aborted and retried.
UPDATE
In this case this means that it (incorrectly in my opinion)picks up
the latest version of ref1 and completes, returning r1=3.
So it seems that the concerns raised on reddit were valid, because clojure
doesn’t strictly follow the behaviour described in the documentation.
Luckily there is a way to get the desired behaviour - add some history to the
refs…
In this case this means that the transaction picks up the latest
version of ref1 and completes, returning r1=3. This is a
‘correct’/consistent result, but the system has done unnecessary work.
So it seems that the concerns raised on reddit were valid, because clojure doesn’t strictly follow the behaviour described in the documentation.
There is a way to get the desired behaviour, but it feels like a hack. By adding history to the ref, the read-only transaction completes first time. To me, this change in behaviour, which isn’t incorrect exactly, is wasteful of resources…
END UPDATE
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
Although this works, and would apply to our original model for accounts, I don’t really like it.
There’s a better way to model this; Rather than make each account a ref in it’s own right, store the collection of accounts under a single ref and update the whole collection for each transfer.
Here’s how a simple implementation of that might look:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
The transfer function would be updated accordingly…
1 2 3 4 5 6 7 8 9 10 | |
In this post we’ve investigated consistency between refs, found a
potential problem with the clojure runtime and eventually improved out
model to avoid the problem.
UPDATED: Text above updated at 15:45GMT 17 Apr 2012 following comments from Antti-Ville Tuunainen
In the next post we’ll discuss a subtle requirement when dealing with refs. Namely - How do you ensure that a ref hasn’t changed during a transaction?
Clojure has a variety of features that help in the creation of programs that deal with concurrency. This post is going to focus on Software Transactional Memory but the nature of these problems is that many parts act together to provide the solution, so expect some of the other concepts to leak in…
Software Transactional Memory (STM) is a concurrency control technique
analogous to database transactions for controlling access to shared
memory in concurrent computing. It is an alternative to lock based synchronization.
STM allows updates to multiple values in memory and for those changes to become visible atomically to other threads at the same logical moment. Similar to database transactions, if for some reason all the updates can’t be made then none of the updates are made.
The canonical example of a transaction is in banking - where you’d like to move amount X from your account to my account.. We’ll use that as our example, because conceptually everyone is familiar with it 1.
Implementation of STM is not a solved problem in computer science at present. There is active research on how best to achieve it. Clojure opts for an approach based on Multiversion concurrency control (MVCC). MVCC maintains multiple (logical) versions of data referenced in a transaction. For the duration of your transaction you see a snapshot of what the data looked like at the start of the transaction. MVCC is an obvious choice here when you consider that the pervasive use of persistent data structures in clojure get you most of the way to this without much further work.
The main constructs for STM are ref and dosync. Lets have
a look at an example…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
You can see here that we’ve declared two accounts and seeded account1
with 100. The (transfer) function takes an amount, a from
account ref and a to account ref and then uses alter on both
refs to deduct amount from the from account and adds the same
amount to the to account. This code runs in a single thread, but
consider what could happen if another thread ran between the two
alter statements and made changes to the values stored in the two
acccounts. Without the protection of STM, it would be easy to lose an
update to either or both accounts.
Another example; Suppose that at the end of day, the bank wanted to run a report on the balances in all accounts. Potentially such a report could take a long time to run, but during the time the report runs, transactions should still be possible on the accounts and for the purposes of our report we should see a consistent view of the data.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Consider the diagram below. You’ll see three transactions shown in
pink boxes. You’ll also see the various versions of the ref in the
left hand column. When a transaction is started via (dosync) the
versions of the refs are captured. These captured values are the value
that (deref) will return for the duration of the transaction.
(i.e. reads of refs are consistent within a transaction).
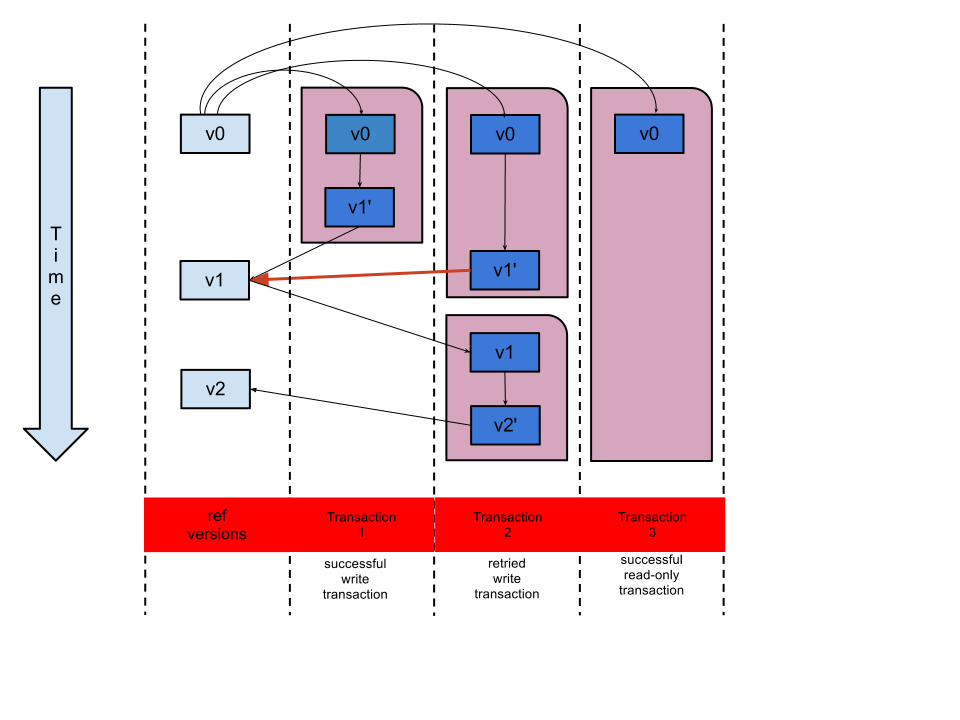
Lets look a the two leftmost transactions. The transactions start at the same time, both access the same ref, so both get a copy of version 0 of that ref. Within the transaction some processing is performed that results in the value of the ref being updated. The first (leftmost) transaction finishes first, so wins the race to update the ref with it’s new value. When the second transaction finishes it tries to write it’s value, but the write fails (red arrow in the diagram) because the version of the ref is not what was expected. In this case the transaction is re-tried. Note that when the transaction re-tries, it first gets a copy of the (new) version of the ref. ie. it sees the changes made by transaction 1. Since no other transaction attempts to update the ref, this time transaction 2 completes.
You’ll also see that while all that was going on a third transaction was running, but the processing in that transaction didn’t update the ref, so no retry was required and the transaction ran to completion.
If the values stored in the refs are persistent data structures holding multiple logical versions of those structures in memory can be efficient, because of the inherent structural sharing in those structures. However, extra resources are being used and in some scenarios that may cause problems. When declaring refs you have the option to pass a couple of options to tune how the runtime will manage the history (i.e. the number of versions as discussed above) associated with the refs.
1 2 3 4 5 | |
This allows you to improve marginal performance in the presence of read-faults by taking the pre-allocation hit up front and limit how resources are allocated to history
There are some concurrency use cases where you can afford to be a bit
more relaxed to gain some performance. For example, imagine you were
keeping a transaction log through the day. You might be relaxed about
the order of transactions in the log if you knew that the final
balance was always correct. Basically if you receive two deposits of
$100 and $50 you won’t mind too much if they are logged as $100 then
$50 or $50 then $100. The deposit of the two transaction is
commutative and clojure provides a concurrency operation
(commute) for just such cases….
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
The thing to note about (commute) is that when the function is
called it sets the in-transaction value of the ref, but the actual
change is applied at commit time, by running the function passed to
commute again with the latest ref value. This means that the value
you calculate in your transaction might not be the value that is
finally committed to the ref. This needs careful thought. You need to
be sure that your processing doesn’t rely on seeing the latest value
of the ref.
Finally, you’ll be wondering about that (println) in the example
above. What happens to side-effects like that in the event of a
transaction re-try? Very simply the side-effects will happen again. In
the above case this probably doesn’t matter, the log will be
inconsistent but the real source of data (the ref) will be correct.
Clojure provides a macro to help here, namelyio!. This allows you
to flag code that musn’t run inside a transaction. You can use this
to protect yourself when you inadvertently call side-effecting code in
a transaction.
For example:
1 2 3 4 5 6 7 | |
To properly acheive IO from within a transaction you’d fire messages to agents from within the transaction. Agents within clojure are integrated with STM such that messages are sent if transactions succeed and discarded on transaction failure. This will be the subject of a future blog post
UPDATE: Check out the follow on post here to discuss possible issues with ref consistency in clojure
1 Interesting sidenote here: This canonical example is not how financial services firms actually work, for small amounts they wave the amounts through and sort out discrepancies in reconcilliation at the end of day. The cost of imposing strict transactions outweighs the losses through errors/fraud. But fixing financial services is beyond the scope of this article…
This post is a continuation of the previous post at the London clojure dojo.
When we left the story, we had generated a HTML table with id attributes
related to the (x,y) co-ordinates and CSS classes to determine the
colour.
We have some methods on the client side relevant to updating the table
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
The first method fill-random creates a sequence of values, one
for each entry in the grid. The possible values are either :alive
or nil
The update-view method, which is a callback when the grid data has changed,
maps across the grid sequence and calls set-cell-state for each
entry. Note that we use map-indexed instead of map to get both the
index and the state and then infer the (x,y) co-ordinates from the
index. The other point to note here is that, since map-indexed
produces a lazy sequence we need to force the evaluation with
doall or we never see the side effects (i.e. the calls to set-cell-state).
So now we have a data representation and a call back that updates the grid with new values. The final piece of the puzzle is the code that creates the next generation based on the current one. i.e. applies the rules of game of life. Let’s remind ourselves what the rules are:
We first we need a method to find adjacent cells then we can count the
values in those adjacent cells and apply the rules above. There seem
to be many ways to skin this cat. A simple implementation might be to
calculate multiple offsets from the current index. The juxt function lets you do
something like this, but it doesn’t quite work as expected…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
a different approach is needed.
Consider these two examples. In each case we’d like to find the indices adjacent to the number highlighted in red. i.e. the squares highlighted in blue.
-c1 -r1 | c0 | c1 | c2 | c3 | c4 | c5 |
r0 | 00 | 01 | 02 | 03 | 04 | |
r1 | 05 | 06 | 07 | 08 | 09 | |
r2 | 10 | 11 | 12 | 13 | 14 | |
r3 | 15 | 16 | 17 | 18 | 19 | |
r4 | 20 | 21 | 22 | 23 | 24 | |
r5 |
-c1 -r1 | c0 | c1 | c2 | c3 | c4 | c5 |
r0 | 00 | 01 | 02 | 03 | 04 | |
r1 | 05 | 06 | 07 | 08 | 09 | |
r2 | 10 | 11 | 12 | 13 | 14 | |
r3 | 15 | 16 | 17 | 18 | 19 | |
r4 | 20 | 21 | 22 | 23 | 24 | |
r5 |
Note that in the second example, some of the adjacent squares are off
the board - we shouldn’t return indices related to those squares. If
we alter our representation from a single sequence to a sequence of
sequences we can then operate on the elements in each row. By
discarding rows (highlighted in green) and columns (highlighted in
pink) we should be left with the required values. Discarding from the front
of a sequence is easily achieved with the drop function and
discarding from the end of a sequence via drop-last. There’s also
a useful feature of those functions that if you pass a negative index
nothing happens. This means we don’t need to worry about validating
the count passed to drop or drop-last
1 2 3 4 5 6 7 8 | |
So by combining that all together we can drop rows before and after those we’re interested in and similarly with columns. This is what I came up with
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Great! we solved the adjacency problem……or have we? Lets check the performance characteristics of the two approaches.
1 2 3 4 5 6 7 | |
Quite a difference and since we’re applying this function once for
each cell, this difference can easily accumulate. But since the
adjacent indices are static values for a particular grid
we can easily memoize the adjacent-indices function to avoid
recalculating known values…
1 2 3 4 5 6 7 8 | |
Having solved the adjacency problem, if should be fairly simple to calculate the states of each cell in the next generation by applying the rules.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
The final piece is to add a watch to the *grid* atom so that the
update-view callback is fired everytime the grid updates and also
to update the model regularly using a timer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
See the final version in action here
All code on github details in the README
Last night was the monthly London Clojure Dojo. The format will be familiar to anyone who’s been to a dojo. 30 odd developers meet up after work, devour large quantities of pizza and a little beer then split into groups to solve an interesting problem. The problems are suggested over pizza and via a couple of rounds of voting are narrowed down to a couple to focus on.
Last night the problems where Conway’s Game Of Life and Monte Carlo methods
The team i was allocated to decided to tackle Game Of Life. The added twist for this dojo was that the solutions were to be developed in ClojureScript
Now I’ve discussed previously there are still
quite a lot of rough edges to clojurescript, so the first challenge
was getting a development environment up and running. Even tho I had a
working clojurescript one environment I
felt it was a little heavyweight for this dojo. We opted for
lein-cljsbuild
instead. A quick git clone and some minor tweaks and we were up
and running.
We realized that there were two possibilities for drawing the game board.
From my experience I knew that wrangling the DOM was going to be easier that accessing the javascript canvas api, so that’s the approach we took.
We used hiccup to generate the table on the server side. This looks this:
1 2 3 4 5 6 7 8 | |
Points to note:
table-generation function we are assigning the CSS class
of ‘dead’. The idea is that we’ll just toggle the CSS class from
live -> dead -> live as each generation progresses.id to each <td> that is basically the
(x,y) co-ordinate of the cell. This allows us to find the node
by id and set the class attribute like this (set-cell-state 10 23
:live)And that’s it for the server side code! It generates a table looking something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
which renders like this:
Next we move to the client side code and this, inevitably, is where those rough edges I mentioned earlier start to show through. The first problem was that clojurescript has a slightly different interop form because of the nature of javascript objects. Because methods and properties are both entries in the hash associated with the object, you need to distinguish between
this leads to these forms:
1 2 3 4 5 6 7 8 9 10 11 | |
I think it’s fair to say this was a significant source of confusion for everyone.
Before we ran out of time we managed to get the grid rendering some random generated data. By refreshing the page we could a least simulate the real operation!
In part 2 I’ll talk about how I took the smoke and mirrors skeleton demo’d at the dojo into a working demo.
UPDATE: read part 2
I stumbled on this answer on stackoverflow to the question ‘how to convert byte size to human readable form in java.’
The code looks like this:
1 2 3 4 5 6 7 | |
The answer is pretty sweet in java. I wondered what it might look like in clojure….
1 2 3 4 5 6 7 | |
Actually surprisingly similar. The difference is that the clojure code looks familiar whereas the java code looks quite optimized. Simply put in clojure you will tend to write short meaningful code, whereas in java you will have to work hard at it….
I’ve been slowly but surely working through the problems on The excellent 4clojure website. If you’re doing the same, I should warn you that there are spoilers below…
Some of my difficulties are learning a strange API, some are adapting to a functional way of thinking.
An essential part of the learning process is, once you’ve completed a problem, reviewing the other solutions. I’ve selected a few members of the clojure/core team as exemplars to compare myself against. I’m pretty happy if I’m within about an order of magnitude for length of solution compared to the top ranked guys.
So far, when a problem comes up, I can often arrive at a working
algorithm, but struggle to express it in a sensible way in clojure.
Today’s problem,
Pascal’s Trapezoid is such an
example. I realised quite quickly that because clojure allows you to
map over multiple collections at the same time, I can add the input
vector to a copy offset by 1 and i’ll be very close to the solution.
Let’s look at producing one value first. The next value for an input of [2 3 2] should be [2 5 5 2]
1 2 3 4 5 | |
so far so good, we have the middle values. Lets add the first and last values in…
1 2 3 4 5 | |
Hmmm, seems to work, code looks a bit messy, maybe we can use destructuring on the arguments to improve things…
1 2 3 4 | |
Hmmm, code doesn’t look any better. Messy code is a code smell.
Let’s make this thing work as a lazy sequence and see what effect that has.
1 2 3 4 5 6 | |
Well, it works but it looks an absolute mess…
Let’s go back to first principles. We realised that basically we want to add the sequence to an offset by one copy. The problem is the first and last digits. How can we handle that?
Well if we could somehow include an unmodified first and last digit
that should do it. Of course addition of 0 to the front of one
collection and the end of the other fits the bill,
so for an input of [ 2 3 2 ] we want to map + over
[ 0 2 3 2 ] and [ 2 3 2 0 ]
So that might look something like this:
1 2 3 4 5 | |
So we have a working version, but the meaning of the code is not immediately evident.
There must be a better way!
Of course it turns out that there is…
1 2 3 | |
What’s going on here? Well the ~@ is the unquote-splice
macro, ~@v means take the elements of sequence v and splice them in
at this point. so if v is [ 2 3 2 ] then `(0 ~@v) -> (0 2 3
2)
Compare to the bindings of s1 and s2 in the
previous verion and you’ll see the similarities.
So are we there yet? Not quite. It turns out that there’s a function
in clojure/core called iterate which generates a lazy sequence of
values by passing the previous result back into the supplied function.
This gives a final version that looks like this:
1 2 | |
Once you understand what’s going on with the unquote splicing, this code looks very clear indeed. Checking with the solutions on 4clojure.com and we see that we’re there!
This ability to splice like this is because of the Code is Data nature of clojure (and other LiSPs). Very powerful….