Clojure has a variety of features that help in the creation of programs that deal with concurrency. This post is going to focus on Software Transactional Memory but the nature of these problems is that many parts act together to provide the solution, so expect some of the other concepts to leak in…
What is STM?
Software Transactional Memory (STM) is a concurrency control technique
analogous to database transactions for controlling access to shared
memory in concurrent computing. It is an alternative to lock based synchronization.
STM allows updates to multiple values in memory and for those changes to become visible atomically to other threads at the same logical moment. Similar to database transactions, if for some reason all the updates can’t be made then none of the updates are made.
The canonical example of a transaction is in banking - where you’d like to move amount X from your account to my account.. We’ll use that as our example, because conceptually everyone is familiar with it 1.
Implementation of STM is not a solved problem in computer science at present. There is active research on how best to achieve it. Clojure opts for an approach based on Multiversion concurrency control (MVCC). MVCC maintains multiple (logical) versions of data referenced in a transaction. For the duration of your transaction you see a snapshot of what the data looked like at the start of the transaction. MVCC is an obvious choice here when you consider that the pervasive use of persistent data structures in clojure get you most of the way to this without much further work.
Why do we need STM?
The main constructs for STM are ref and dosync. Lets have
a look at an example…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
You can see here that we’ve declared two accounts and seeded account1
with 100. The (transfer) function takes an amount, a from
account ref and a to account ref and then uses alter on both
refs to deduct amount from the from account and adds the same
amount to the to account. This code runs in a single thread, but
consider what could happen if another thread ran between the two
alter statements and made changes to the values stored in the two
acccounts. Without the protection of STM, it would be easy to lose an
update to either or both accounts.
Another example; Suppose that at the end of day, the bank wanted to run a report on the balances in all accounts. Potentially such a report could take a long time to run, but during the time the report runs, transactions should still be possible on the accounts and for the purposes of our report we should see a consistent view of the data.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
How does STM in clojure work
Consider the diagram below. You’ll see three transactions shown in
pink boxes. You’ll also see the various versions of the ref in the
left hand column. When a transaction is started via (dosync) the
versions of the refs are captured. These captured values are the value
that (deref) will return for the duration of the transaction.
(i.e. reads of refs are consistent within a transaction).
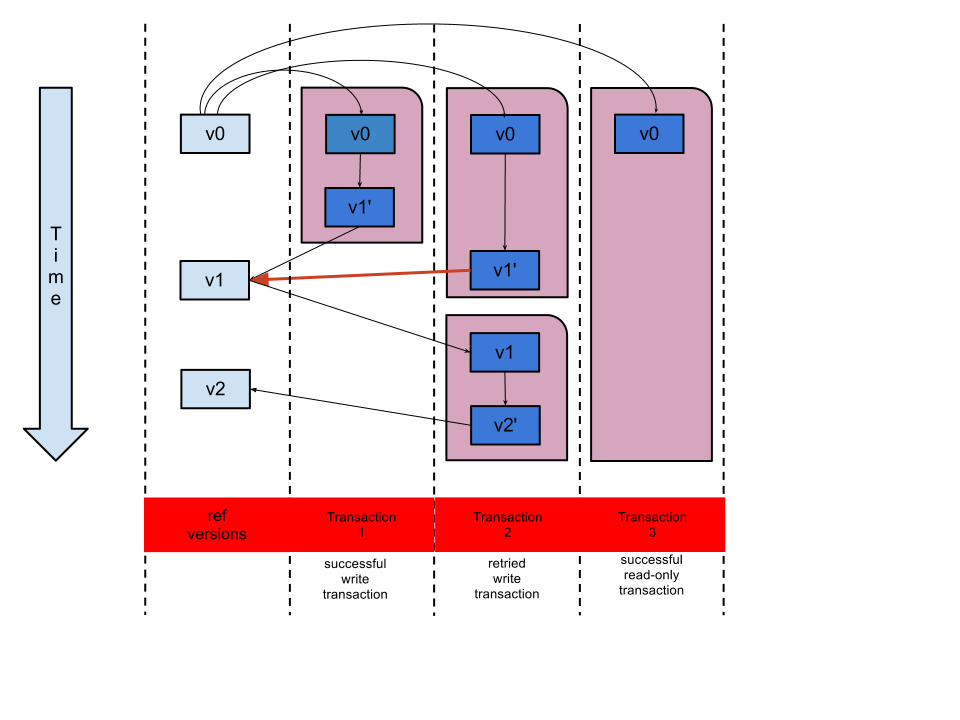
Lets look a the two leftmost transactions. The transactions start at the same time, both access the same ref, so both get a copy of version 0 of that ref. Within the transaction some processing is performed that results in the value of the ref being updated. The first (leftmost) transaction finishes first, so wins the race to update the ref with it’s new value. When the second transaction finishes it tries to write it’s value, but the write fails (red arrow in the diagram) because the version of the ref is not what was expected. In this case the transaction is re-tried. Note that when the transaction re-tries, it first gets a copy of the (new) version of the ref. ie. it sees the changes made by transaction 1. Since no other transaction attempts to update the ref, this time transaction 2 completes.
You’ll also see that while all that was going on a third transaction was running, but the processing in that transaction didn’t update the ref, so no retry was required and the transaction ran to completion.
If the values stored in the refs are persistent data structures holding multiple logical versions of those structures in memory can be efficient, because of the inherent structural sharing in those structures. However, extra resources are being used and in some scenarios that may cause problems. When declaring refs you have the option to pass a couple of options to tune how the runtime will manage the history (i.e. the number of versions as discussed above) associated with the refs.
1 2 3 4 5 | |
This allows you to improve marginal performance in the presence of read-faults by taking the pre-allocation hit up front and limit how resources are allocated to history
Relaxing consistency and side-effects
There are some concurrency use cases where you can afford to be a bit
more relaxed to gain some performance. For example, imagine you were
keeping a transaction log through the day. You might be relaxed about
the order of transactions in the log if you knew that the final
balance was always correct. Basically if you receive two deposits of
$100 and $50 you won’t mind too much if they are logged as $100 then
$50 or $50 then $100. The deposit of the two transaction is
commutative and clojure provides a concurrency operation
(commute) for just such cases….
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
The thing to note about (commute) is that when the function is
called it sets the in-transaction value of the ref, but the actual
change is applied at commit time, by running the function passed to
commute again with the latest ref value. This means that the value
you calculate in your transaction might not be the value that is
finally committed to the ref. This needs careful thought. You need to
be sure that your processing doesn’t rely on seeing the latest value
of the ref.
Finally, you’ll be wondering about that (println) in the example
above. What happens to side-effects like that in the event of a
transaction re-try? Very simply the side-effects will happen again. In
the above case this probably doesn’t matter, the log will be
inconsistent but the real source of data (the ref) will be correct.
Clojure provides a macro to help here, namelyio!. This allows you
to flag code that musn’t run inside a transaction. You can use this
to protect yourself when you inadvertently call side-effecting code in
a transaction.
For example:
1 2 3 4 5 6 7 | |
To properly acheive IO from within a transaction you’d fire messages to agents from within the transaction. Agents within clojure are integrated with STM such that messages are sent if transactions succeed and discarded on transaction failure. This will be the subject of a future blog post
UPDATE: Check out the follow on post here to discuss possible issues with ref consistency in clojure
1 Interesting sidenote here: This canonical example is not how financial services firms actually work, for small amounts they wave the amounts through and sort out discrepancies in reconcilliation at the end of day. The cost of imposing strict transactions outweighs the losses through errors/fraud. But fixing financial services is beyond the scope of this article…